Сказания о локализации — и не только
Еще один блог ГП
Клиент всегда прав |
||||
|
Прочитали название? Знакомый лозунг, не так ли? Нам его на все лады повторяли достаточно долго, чтобы все успели как следует затвердить эту мантру. Ну а теперь забудьте. Кроме шуток, если только не хотите спустить в мусорное ведро свой бизнес, карьеру, профессионализм, репутацию – забудьте навсегда. Я понимаю маркетологов и рекламистов, которым бывает нужно привлечь массы, понимаю отдельных клиентов, которым может быть приятно самоощущение священной коровы, символически компенсирующее факт доения, но суть от этого не меняется. Всякий раз, когда я слышу это заклинание, в реальности обычно выясняется, что служит оно просто ширмой для не слишком щепетильного отношения к делу, более чем вольного ценообразования либо же банальным пиаром (известным еще нашим предкам под названием “лапши на ушах”). В попытках простимулировать, наконец, массового потребителя к выполнению его основной роли – потреблению – бизнес крупный и (в меньшей степени) малый повторяет эту удачную мантру уже давно, и временами даже убеждает себя, что рынок популярных товаров и услуг – это рынок покупателя. Вот только как согласуется с этим упорное стремление самих “вечно правых” клиентов платить больше, предпринимать лишние хлопоты, терпеть в очередях, и все это ради того, чтобы получить за свои деньги не абстрактную “правоту”, а товар или услугу, которые их действительно удовлетворяют или даже превосходят ожидания? Третий десяток лет профессиональной деятельности дает почву для обобщений. Так вот, что им в действительности требуется, даже самые солидные клиенты не знают точно почти никогда. Чего хочется, знает один из десяти. И хорошо, если хоть один из полусотни будет знать, как это должно быть сделано. А самый верный способ загубить дело на корню — это начать вместе с ними метаться в их поисках себя. К профессионалу (если он не практикующий психолог) приходят все-таки не за этим, а за решением конкретной проблемы. Вот ее и нужно решить так, как подсказывает опыт, стандарты и правила отрасли, с максимальной тщательностью и в рамках бюджета. 🙂 Да, клиента можно и нужно попытать, выясняя задачи, которые должен решить перевод. Ему нужно предложить варианты решения, показать возможные пути и раскрыть перспективу. Но любые заигрывания в духе мифологемы из заголовка при этом неуместны абсолютно уже хотя бы потому, что переводят все дело из плоскости решения проблемы в плоскость психотерапии и внушения. И плоскости эти взаимоисключающие, потому что ресурсы исполнителя конечны, так что хорошо он в итоге (и в лучшем случае) все равно сделает что-то одно. А потребность в качественной услуге так и останется висеть в этом маркетинговом тумане увесистой гирей над головой заказчика. Любопытно, что дихотомию эту уловить оказывается довольно сложно коллегам, чье вхождение в профессию пришлось уже на XXI столетие. Казалось бы, уж их рассудок не должен быть зашорен никакими догмами? Объяснения у меня нет, пока в качестве рабочей гипотезы подозреваю, что сказывается агитационная проработка темы в СМИ и общественном сознании. Собственно, и это размышление родилось по мотивам одной такой беседы. Оптимистичного резюме к этим мыслям тоже нет, есть только надежда на здравый смысл и его волшебную способность со временем пробиваться сквозь любой морок. |
||||
|

Немного практической математики |
||||
|
Как пишут в большинстве спецификаций на клавиатуры, ресурс мембранных моделей (95% ассортимента в любом магазине) составляет 5 000 000 нажатий. Что это означает применительно к переводческой работе? Предположим, что длина максимально условного среднего слова — 5 символов. 5 000 000 / 5 = 1 000 0000 слов Предположим, что средний переводчик за день одолевает около 2,5k слов плюс еще успевает набрать слов 500-1000-до-бесконечности помимо прямой производительной работы. 🙂 1 000 000 / 3 000 = 333,33 Понятно, что настоящие математики над такими исходными допущениями смеются еще в детском саду. Понятно, что нагрузка будет неравномерной, и максимальный износ придется на буквенно-цифровые блоки, пробел и символы пунктуации. Тем не менее, в любом раскладе получается, что даже работающий не в самом интенсивном режиме переводчик имеет вполне ощутимый шанс “убить” свой рабочий инструмент менее чем за год. И практический опыт подсказывает, что допущения эти на деле не так уж далеки от реальности. К чему посещают такие раздумья? Да просто однажды начинаешь замечать, что когда-то ласкавший слух шепот любимой MS Ergo 4000 сменился ее же натужным скрипом и дребезгом. И ничего тут не поделать, все закономерно. Остается только опять отправиться в магазин за ее сестрой-близнецом. Или все-таки в очередной раз поискать совершенства? |
||||
|
Про память |
||||
Память, не компьютерная, человеческая — и радость наша, и наказание. Второй день смутное ощущение, что в мире стало меньше света. Как будто перечитываешь ту часть нескончаемой Поттерианы, где гибнет Дамблдор, только с одним отличием — все по-настоящему. Вспоминается давний вечерний разговор, совмещенный с разглядыванием солнца, заходящего в воды залива: — Ты не можешь уйти так, чтобы все не развалилось. Твои соратники профессионалы и хорошие люди, но они не ты. Это как часы — все работает какое-то время, но без часовщика рано или поздно идет вразнос. — Не думаю. Если так, это значило бы, что я никого ничему не научил. Хоть бы он снова оказался прав. R.I.P., Steve. |
||||
|
Про инновации |
||||
|
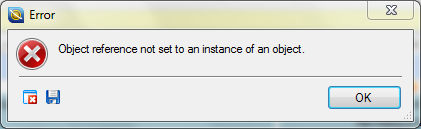
— Что же из этого следует?— Следует жить, Нет-нет, это не обзор новой кошки. И даже не список граблей, щедро разложенных на входе для всех желающих перейти на новую версию. Просто рефлексия по поводу знакомства с новой версией известного инструмента — вдруг кому-то сэкономит минуту-другую. Но обо всем по порядку. Новую версию SDL Studio 2009 ждали. Ее анонсировали задолго до выхода, на форумах ее хвалили и ругали еще не видя в глаза, но все равно было интересно — а что получится. Список изменений куда длиннее списка того, что осталось нетронутым, так что это фактически принципиально новый продукт. Самый первый блин вышел по пословице, но после SP1 благоприятных отзывов стало больше. Благодаря одной молодой и подающей надежды отечественной компании приобрести/обновить продукцию SDL стало возможно по вменяемой цене, так что наступила пора знакомиться. В комплект издания Freelancer входят: (барабанная дробь) SDL Trados Studio 2009, SDL Multiterm Desktop, SDL Trados 2007 Suite. Последнее немаловажно для тех, у кого уже накоплен багаж переводов. Во-первых, перейти сразу на новую кошку получится не у каждого, а работать надо. Во-вторых, конвертировать старые залежи файлов и ТМ без него в новый формат просто не удастся. Сначала в SDL пугали тем, что лицензия на Suite 2007 будет ограниченной по сроку, потом чуток одумались, в общем, сейчас она выдается без ограничений по времени. При установке версии Freelance Studio 2009 можно выбирать до пяти рабочих языков и лучше отнестись к этому выбору серьезно — потом изменить его без переустановки не получится. Еще один забавный момент — в XXI веке передовой продукт SDL не позволяет выбрать каталог, в который его следует установить. Во всяком случае, процедура установки напрямую такой выбор не предлагает, хотя еще предыдущая версия вполне поддерживала подобное вольнодумство. Активация обеих версий — совершенно отдельное удовольствие, но хотя бы знакомое, в этой процедуре никаких изменений не произошло. Жаль, но файл лицензии сейчас использовать уже не дают, если не взять техподдержку за горло. Он, между тем, был гораздо удобнее действующей сейчас методики. Предыдущую версию Studio, кстати, нужно ставить первой. Затем необходимо хотя бы раз зайти в Workbench и создать идентификатор пользователя. Иначе первая же попытка перевести свои базы ТМ в новый формат закончится вот таким сообщением:
Странно, но в новой разработке нет собственного средства для составления баз из накопленных переводов, предлагается использовать для этой цели старый добрый WinAlign или SDL Align. Также не получится использовать одну базу в двух направлениях: если у вас база для перевода с английского языка на русский, сразу подключить ее для перевода с русского на английский новая система не даст. Надо отметить, что некоторые подводные камни, подстерегающие счастливых пользователей Studio 2009, как и пути обхода, в SDL заботливо описали в руководстве по миграции (каких-то 248 страниц), но его можно прочесть только после покупки продукта, это описание на сайте производителя для свободной загрузки не предлагается. Напрасно, можно было серьезно сэкономить время и нервы техподдержке, ну да это их дело.
В самом интерфейсе Studio 2009 ориентироваться довольно легко, если сразу забыть о привычках и рефлексах, накопленных за время работы с предыдущими версиями. Это другой продукт, в чем-то более сложный, в чем-то — упрощенный, есть в нем и аспекты, напоминающие о ближайших конкурентах (DV, Across). Знакомство с новинкой облегчают вводные учебные описания. Некоторые подразумевают использование проекта-образца, входящего в стандартную установку. Так вот, здесь некоторых тоже поджидает сельскохозяйственный инвентарь. Если на этапе установки вы не выбрали рабочими языками японский, французский и немецкий, то попытка открыть любой файл из проекта (хоть для перевода, хоть для просмотра) закончится вот этим:
Маркетоидный маразм, скажете вы? Ничего подобного, четкое сегментирование рынка, ответят в SDL. Бог с ним, переходим к проектам. SDL Studio 2009 вся вертится вокруг проектов, которые делятся на пакеты. Мысль здравая, в пакет входит все необходимое (исходник, задание, базы, метаданные), но вот их разнообразие удивляет — пакеты для перевода, для проверки, для отправки и возврата, для.. через пять минут от них начинает рябить в глазах. Идея хороша, спору нет, но зачем плодить столько разновидностей? Внутри у них ведь одно и то же — разница по сути лишь в задании, которое назначается исполнителю. Возможно, впрочем, что хотя бы менеджерам БП все это пригодится. Проекты можно удалять из списка, при этом на диске они остаются. Это удобно, пожалуй, позволяет не тревожиться особо насчет неосторожных движений в ходе работы. Создать новый проект можно только в пустой папке — тоже мысль здравая, но предупреждать об этом стоит заранее, при выборе места, а не после выбора, вот таким образом:
Ладно, пробуем создать проект. Беру оригинал переведенного давным-давно файла (Ru->En) из личных закромов, к нему конвертированную парой минут раньше его же родную базу и…
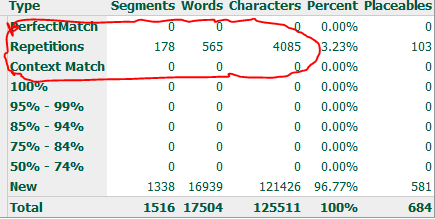
По-моему, несовпадения в пределах 20% вполне можно списать на расхождения в правилах сегментации и анализа, это приемлемо. 11% от всего объема — нормальный и даже неплохой показатель для ненастроенной кошки, которой дали первое задание. Но вот количество повторов озадачивает. Скрин выше — это результат для пары Ru-En(US). А вот для пары Ru-En(UK) на том же файле кошка выдает такой анализ:
Вот это уже ставит в тупик. Товарищи из SDL, в нашем деле за неточную статистику бьют канделябром вообще-то! Понятно, что причина в базе — если ее отключить, статистика становится идентичной, но ведь обычно материал анализируется как раз с базами накопленных переводов. В общем, этот аспект в новой кошке требует как минимум внимательного пригляда и перепроверки. Смутило настойчивое кошкино стремление помечать все сегменты как завершенные на выходе из любого режима. Из редактуры — как отредактированные, из sign-off — как утвержденные. А если я не успел за один раз проверить весь документ? Они ведь и большими бывают, знаете ли. Вот к чему нет особых претензий, так это собственно к интерфейсу для перевода. Пускай он цельнотянутый из DV, где почти все это было еще несколько лет назад, но автоподстановка, автопоиск, динамическое распространение переводов на повторы — это очень удобно. Импорт сложных файлов, работа с тегами, таблицами, списками, отражение структуры документа — все это субъективно стало делать значительно легче. Возможность переключиться в полноэкранный режим тоже не лишняя. Real-time preview, конечно, работает через пень-колоду, а на выходном файле чаще не работает вовсе, но это уже не только кошкина вина — какие файлы приходят иногда в работу, знают все, кому доводилось заниматься переводом. Когда все действует как задумано, работать комфортно, а информация действительно отображается удобно, хоть и заставляет пожелать себе какой-нибудь широкоэкранный монитор с диагональю дюймов так на 40-50. Как следствие, в интерфейсе мне лично очень не хватает возможности масштабировать текст в ячейках исходника/перевода. Скорее всего, где-то в кошке эта функция закопана, но интуитивно найти ее сразу не получилось. Еще интересный момент — в процессе работы кошка по умолчанию вносит новые сегменты в ТМ текущего проекта, не трогая исходную (основную) память. После завершения проекта можно решить, куда отправлять новые сегменты. Основная ТМ при этом не замусоривается промежуточными и неудачными вариантами. Или все равно засоряется, но ощутимо меньше. 🙂 Работает SP1 в меру стабильно, космических скоростей не показывая, но все успевая. Конечно, не обходится без любимого фокуса SDL, маловразумительных сообщений движка .Net об ошибках, особенно на сложных файлах HTML:
Экспорт заслужил похвалу — в кои-то веки изделие SDL без особых настроек и бубнотрясения не убивает в выходном файле коды, перекрестные ссылки, поля, не сдвигает картинки и не уносит подписи к ним на пару глав вперед/назад. Это определенно прогресс, тут ставлю плюсик без колебаний, хотя наверняка будут случаи, где грабли все-таки покажутся на свет.
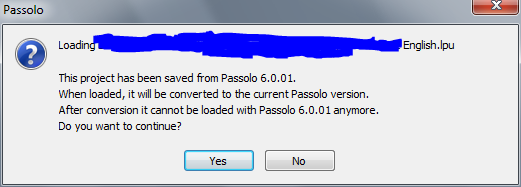
Наконец, добираемся непосредственно к той части комплекта, что отвечает за локализацию. Суровые парни из SDL решили включить в комплект Studio целую новую программу — Passolo 8, в редакции Essential, то есть обрезав ей предварительно все, что только можно. Открываем что-нибудь из старых запасов:
Хм… парни в SDL, вероятно, очень добросовестно подходят к процессу перевода и ждут того же от каждого менеджера проекта. Теперь, чтобы разослать материал на перевод, например, в трех языковых направлениях им нужно будет сделать не один пакет .tbu, а три .lpu — со всеми дальнейшими радостями их объединения, когда переводы будут готовы. Иначе переводчики просто не смогут открыть пакет. А ведь направлений перевода может быть и больше. Определенно не самая лучшая идея, ведь менеджерам хватает головной боли и без жонглирования разными вариациями пакетов с одним и тем же. Ладно, идем дальше, открываем .lpu: Я понимаю, что парни в SDL, как и все прочие, хотят денег. Ну так пусть заработают их функционалом, а не занимаются шантажом пользователей. Я уж не говорю о том, что процентов 90 этих самых пользователей (и разработчиков ПО, между прочим) как раз и сидят на старых версиях их же приложений и как-то не горят желанием в одночасье переходить на новые. Значит, полная обратная совместимость с ними — не роскошь, а обязательное условие. Если для перехода на новое ПО придется перетаскивать на него же всех контрагентов, выкидывать в мусор все свои многолетние наработки либо начинать их копить с полного нуля…. то этому ПО нужно быть значительно более отлаженным и продуманным, чем предлагаемый SDL комплект. По локализационной составляющей категорический незачет — без всемерной поддержки БП к использованию непригодно. Причем непригодно не из-за дефектности продукта (Passolo — программа сама по себе вполне нормальная), а по ущербности и недальновидности маркетоидных ограничений, навязанных пользователю. Видимо, кризис еще далеко не все прочистил в некоторых мозгах. В сухом остатке наблюдаем довольно интересную концепцию, впечатление от которой изрядно портят мелкие недоделки в реализации и глупейшие маркетинговые ограничения. Шероховатости в программном коде, надеюсь, со временем вычистят (ждем SP2?). Когда уволят гениев из отдела маркетинга — до разорения SDL или уже после, вместе со всеми — еще один занимательный вопрос. Он даст ответ на другой — будут ли решения SDL широко использоваться в следующие 5-10 лет. Пока что, как ни парадоксально, Studio 2009 вполне работоспособна на простых задачах, а субъективные впечатления от нее по большей части положительные. Использовать ее в работе я, скорее всего, буду и дальше. Вместе с тем, производитель очень предусмотрительно поступил, включив в комплект и предыдущую версию (Suite), она там совершенно точно не лишняя.
Сама попытка слить воедино разрозненный зоопарк программ и утилиток достойна поддержки и одобрения. Получилось ли? Время покажет. Пока начало выглядит многообещающим, несмотря на избыток шероховатостей и упущений. Innovation delivered. Осталась мелочь — только довести эту новацию до применимости реальными людьми, а не сферическими переводчиками в вакууме.
|
||||
|
 Сам перенос данных проходит без особых плясок с бубном, импортируются и базы Trados, и SDLX, и TMX 1.4b, и даже текстовые файлы (последние на практике не проверял). Однако прозрачности в этот процесс добавить не помешало бы. Вот, к примеру, стандартное сообщение об успешном импорте базы:
Сам перенос данных проходит без особых плясок с бубном, импортируются и базы Trados, и SDLX, и TMX 1.4b, и даже текстовые файлы (последние на практике не проверял). Однако прозрачности в этот процесс добавить не помешало бы. Вот, к примеру, стандартное сообщение об успешном импорте базы:  И вроде бы все хорошо, но где, черт возьми, мне теперь искать еще 124 записи, 10% базы, в которой каждый сегмент полит слезами и потом? Какие именно сегменты оказались недостойными войти в прекрасный новый мир? Почему? Ответом на эти вопросы новая кошка себя не утруждает, видимо, не царское это дело. Угадать, на какой базе потеряются при импорте сегменты, не получится — явление совершенно спонтанное. Есть мелкие базы, которые спокойно импортируются до последней буквы, есть крупные. И в то же время на половине баз из любой случайной выборки возникают вот эти потери. Надеюсь, дело в алгоритмах анализа совпадений, а не в кривизне фильтров импорта.
И вроде бы все хорошо, но где, черт возьми, мне теперь искать еще 124 записи, 10% базы, в которой каждый сегмент полит слезами и потом? Какие именно сегменты оказались недостойными войти в прекрасный новый мир? Почему? Ответом на эти вопросы новая кошка себя не утруждает, видимо, не царское это дело. Угадать, на какой базе потеряются при импорте сегменты, не получится — явление совершенно спонтанное. Есть мелкие базы, которые спокойно импортируются до последней буквы, есть крупные. И в то же время на половине баз из любой случайной выборки возникают вот эти потери. Надеюсь, дело в алгоритмах анализа совпадений, а не в кривизне фильтров импорта.
 Да и возможность очистить выбранную папку под проект тоже не помешала бы — для ее реализации вовсе не нужно миллионных вложений в R&D.
Да и возможность очистить выбранную папку под проект тоже не помешала бы — для ее реализации вовсе не нужно миллионных вложений в R&D.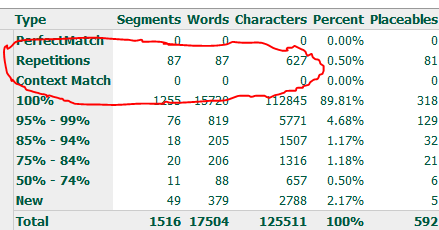
 После сообщения проблемный файл, как правило, закрывается, и переводить его кошка не дает. Очевидно, нужно подкручивать настройки.
После сообщения проблемный файл, как правило, закрывается, и переводить его кошка не дает. Очевидно, нужно подкручивать настройки.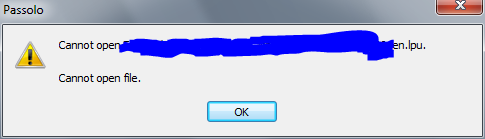 Ну что же, накладки возможны, совсем уж безоблачной жизни никто и не ожидал. Пробуем дальше:
Ну что же, накладки возможны, совсем уж безоблачной жизни никто и не ожидал. Пробуем дальше: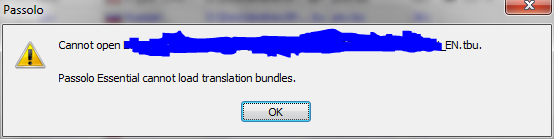
 Вот на этом окошке мне, признаюсь, выдержка изменила, и в SDL отправилось письмо с кратенькой характеристикой их умственных способностей. Пускай формат в новой версии программы мог измениться, пускай его надо конвертировать, но зачем конвертировать тот же самый файл? Почему бы не дать кнопочку для надругательства над его копией? И, наконец, если это уж совсем невозможно, почему бы не разблокировать функцию экспорта для сохранения в формат более ранних версий? Почему выбор Export в меню File служит только для вывода сообщения: «The function ‘Export…’ is only supported by the SDL Passolo Professional or Team Edition»??
Вот на этом окошке мне, признаюсь, выдержка изменила, и в SDL отправилось письмо с кратенькой характеристикой их умственных способностей. Пускай формат в новой версии программы мог измениться, пускай его надо конвертировать, но зачем конвертировать тот же самый файл? Почему бы не дать кнопочку для надругательства над его копией? И, наконец, если это уж совсем невозможно, почему бы не разблокировать функцию экспорта для сохранения в формат более ранних версий? Почему выбор Export в меню File служит только для вывода сообщения: «The function ‘Export…’ is only supported by the SDL Passolo Professional or Team Edition»??
Выбор момента |
||||
|
Иногда пишут или посещают «в реале» замечательные, милые люди — разработчики ПО. Обычно ситуацию они обрисовывают очень быстро и четко: «У нас есть хорошая разработка (программа, портал, сервис), хотим ее продавать для зарубежной аудитории, нужна локализация». Начинаю тактично выяснять: «А что было сделано при проектировании для дальнейшей локализации — глоссарии, ресурсы, база терминологии, стандартный порядок составления документации». В 70-80% случаев выясняется, что это все было отложено на «светлое будущее», но «наши программисты прекрасно владеют языком, они перевели все пункты меню в интерфейсе». Тогда приходится честно сообщить: «Мне очень симпатичны вы и все, что вы делаете, но с локализацией вы дико запоздали. Теперь, кто бы ни занялся этим делом, сначала придется наверстывать упущенное, а упущена масса совершенно необходимых в качественной локализации этапов и очень много времени. Готовы к этому? Тогда давайте работать». Иные удивляются: «А нам в компании N сказали — платите М денег, давайте исходники, и все будет без проблем в лучшем виде». Ну что тут остается делать? Вспомнить сотни бестселлеров, наших и зарубежных, угробленных на корню «русефекацией» и «локализацией»? Объяснить, что локализация без активного участия разработчиков — миф, видимость, мыльный пузырь, который лопается от первого же прикосновения и любых проблем? На миг чувствую себя злодеем, рассказывающим первокласснику, что Деда Мороза не существует. Подавляю первый порыв откровенности, желаю удачи с N, приглашаю обращаться, если что-то не заладится. С некоторыми встречаемся снова через полгода, год, максимум два, начинаем работать — делать то, что следовало бы сделать еще года три-четыре тому назад. Да, в разработке ПО все происходит быстрее, чем в традиционной индустрии — люди быстрее наступают на грабли, быстрее начинают понимать, что им действительно нужно. На наше общее счастье, там обычно есть шанс наверстать то, что однажды было упущено. Глубокое заблуждение — думать, будто локализация сводится к переводу слов одного языка на другой. Это можно делать, и некоторые так и поступают, но результат не будет продуктом, его нельзя продавать, а по большому счету не стоит и вообще людям показывать, чтобы не портить о себе впечатление. Локализация ПО — это прежде всего концепция, модель адаптации программы под другую ментальность. Перевод на другой язык в этом процессе — лишь одна из граней. Это не высшая математика, а совершенно естественный вывод, который сделает любой здравомыслящий человек, лишь немного задумавшись. И вот вопрос — почему эти элементарные вещи не объясняют там, где готовят разработчиков и управленцев для отрасли? |
||||
|
Люди и кошки |
||||
|
Computer-assisted/aided tools, CAT, в просторечии — «кошки». Они с нами уже давно, делают массу рутинной работы и, чего скрывать, изрядно облегчают жизнь. Почти любой переводчик хотя бы слышал о системах вроде Trados, DejaVu, SDLX, Transit, OmegaT.. Почему тогда столь полезные в хозяйстве «животные» до сих пор вызывают неоднозначную реакцию? Все дело в людях, в неоправданных ожиданиях одних и необоснованных опасениях других. Не секрет, что в индустрии перевода кошки появились на свет и прижились как суррогат, заменитель интеллектуальных систем перевода, которые пока особых успехов не продемонстрировали. Даже лучшим представителям последних (aka Promt) требуется долгая тренировка и тщательный подбор материала, иначе интеллектуальная и недешевая программа уверенно выдает заказчику «гуртовщиков мыши» — и плевать хотела на то, что вообще-то речь в тексте идет о драйвере. Если затраты на подготовку и проверку перевешивают выигрыш от автоматизма и скорости, то и польза от такого ПО становится весьма сомнительной. Другое дело — компьютерные кошки. Как и их живой прототип, не претендуя на роль венца творения, они просто делают то, что им удается лучше всего: скрупулезно собирают в базу-копилку термины и переводы, подставляют их при повторах, дают подсказки, приглядывают за качеством, в меру сил разбирают экзотические форматы входных файлов. Подчеркну — ни одна кошка по определению не претендует на то, чтобы заменить человека. Проблемы начинаются тогда, когда кошек начинают использовать не по назначению. Бизнес воспринял этих забавных зверюшек как очередное средство оптимизировать затраты — большая ошибка. На первый взгляд, все вроде бы логично — если фраза или слово переведены однажды верно, то в дальнейшем можно просто подставлять перевод из кошкиных запасов всякий раз, как только нам встретится это слово или фраза. Экономится время, усилия и, главное, деньги. Так? Не совсем. Переводятся не отдельные слова и фразы, переводится смысл целого. И чтобы перевод был корректным, не резал глаз и не раздражал читающих, он должен соответствовать окружению — контексту. Контекст многослоен, он состоит из ближайших фраз, абзацев, разделов, глав. Контекст изменчив — даже пара новых строк может потребовать пересмотра главы, где они добавлены, а то и глав, которые на нее ссылаются. Чтобы корректно донести смысл уже знакомой фразы в новом контексте, может потребоваться совершенно другая формулировка — новый перевод. Но вот загвоздка, только человек может определить, когда это необходимо делать — кошке такая мыслительная деятельность пока не под силу. Да, некоторые из лучших (и самых дорогих) представителей породы пытаются анализировать целые абзацы. При этом предполагается, что, если изменений в абзаце нет, а перевод для него в базе есть, то и подставлять его можно с уверенностью. Ну а как кошке объяснить, что изменить смысл этого абзаца может не только его содержимое, но и предыдущий абзац, параграф на пять страниц дальше по тексту, а то и вся концепция документа, которая в новой редакции стала иной из-за пары новых терминов, введенных где-то в начале? Ответ — никак, кошки не для этого предназначены. Они — для рутинной работы. Никто не посылает кошек реальных, домашних, в поле собирать урожай. Их специализация — мыши. В точности так же дело обстоит и с кошками компьютерными, их удел — контроль качества. Вот в этой области у кошек конкурентов нет, даже человеческое внимание иногда ослабевает, тогда как правильно настроенная кошка всегда изловит случайную ошибку. Людям же остается извечная человеческая обязанность, которую никто с них не снимал — анализировать материал и думать. Бездумная подстановка совпадений из баз — верный способ получить шлак в переводе на выходе, с кошкой или без нее. Классический диалог между переводчиком (П) и менеджером проекта (МП):
Стоит ли говорить, что в 2/3 случаев ничего потом не происходит, документы сдаются, проекты успешно завершаются, а однажды попавшие в базу глупости и переводы, просто утратившие актуальность, так и кочуют из проекта в проект как переходящее знамя? Кошка ли в этом виновата? Нет, человеческий фактор и авральное планирование. Еще раз, кошка — не средство сэкономить. Это, прежде всего, средство сделать более качественный продукт. Сделать его быстрее, точнее, логичнее и удобнее. За счет высокотехнологичного процесса превзойти конкурентов, затыкающих по старинке недоделки и бреши временными заплатами «до лучших времен». Вот затем, заложив надежную основу для качественного перевода/локализации, не грех воспользоваться и ее материальной отдачей в виде экономии, пускай в рамках проделанной работы это и окажется побочным результатом. |
||||
|
Награда ищет героя |
||||
|
Если когда-нибудь сообщество разработчиков ПО решит учредить и вручать награды за самую медвежью услугу отрасли, какую-нибудь золотую кастрюлю или фигу с «кристаллами Сваровски», у меня есть первый кандидат. Уже много лет испытываю страстное желание ласково поглядеть в глаза тому, кто первый придумал, что «документацию никто не читает». Самое забавное — эта чушь и ересь, похоже, распространяется воздушно-капельным путем среди менеджеров, руководящих проектами разработки. В нашем отечестве зараза, кажется, не миновала никого. Документацию в результате большинство отечественных фирм-разработчиков составляет по остаточному принципу, подверстывая материалы к релизу в стиле _ну-ка-поглядим-что-у-нас-вышло_. Логика понятна — в процессе разработки вроде бы не до усилий, которые не дадут немедленного результата. Да и потом, чего стараться, если все равно «документацию никто не читает»? Попробую вообразить на миг, что автор вышеупомянутого гениального изречения однажды увидит эти строки. Так вот, дорогой друг, у меня есть для тебя потрясающая новость! Документацию читают! Еще как читают, представь себе. Самое интересное — кто это делает. Таких, в основном, можно разделить на две категории: 1) Те, кто хочет разобраться, как же программа должна работать по задумке ее авторов. 2) Те, у кого с программой возникли проблемы. Иными словами, это большинство думающих пользователей. А теперь угадайте с трех раз, кто из них останется пользователем программы, в которой «мануал» и «хелп» запутывают больше, чем помогают, или вообще слабо соответствуют тому, что человек видит на экране. У скольких из них появится желание заплатить за следующую версию? Некоторые компании, переболев и наступив на все мыслимые грабли, все же начинают закладывать подготовку документации и системы помощи в этап проектирования, составлять словари/глоссарии базовых понятий, учат разработчиков и технописов использовать именно ту терминологию, что введена в словарях, в общем, вкладываются в читаемость и понятность документации. Большинство, увы, так и продолжает энергично убивать сотни и тысячи рабочих часов на латание и перелатывание с каждой новой сборкой там, где проще отформатировать все и сделать заново по уму. Стоит ли удивляться только, когда наши передовые безо всяких кавычек продукты обходят на поворотах «непродвинутые» заграничные конкуренты с дружелюбным интерфейсом и понятной системой помощи? |
||||
|