Сказания о локализации — и не только
Еще один блог ГП
Выкиньте Прибор |
||||
|
Картинка из тех, что лучше тысячи слов:
Хотя прибор-то вроде хвалят. |
||||
|
.jpg)
Клиент всегда прав |
||||
|
Прочитали название? Знакомый лозунг, не так ли? Нам его на все лады повторяли достаточно долго, чтобы все успели как следует затвердить эту мантру. Ну а теперь забудьте. Кроме шуток, если только не хотите спустить в мусорное ведро свой бизнес, карьеру, профессионализм, репутацию – забудьте навсегда. Я понимаю маркетологов и рекламистов, которым бывает нужно привлечь массы, понимаю отдельных клиентов, которым может быть приятно самоощущение священной коровы, символически компенсирующее факт доения, но суть от этого не меняется. Всякий раз, когда я слышу это заклинание, в реальности обычно выясняется, что служит оно просто ширмой для не слишком щепетильного отношения к делу, более чем вольного ценообразования либо же банальным пиаром (известным еще нашим предкам под названием “лапши на ушах”). В попытках простимулировать, наконец, массового потребителя к выполнению его основной роли – потреблению – бизнес крупный и (в меньшей степени) малый повторяет эту удачную мантру уже давно, и временами даже убеждает себя, что рынок популярных товаров и услуг – это рынок покупателя. Вот только как согласуется с этим упорное стремление самих “вечно правых” клиентов платить больше, предпринимать лишние хлопоты, терпеть в очередях, и все это ради того, чтобы получить за свои деньги не абстрактную “правоту”, а товар или услугу, которые их действительно удовлетворяют или даже превосходят ожидания? Третий десяток лет профессиональной деятельности дает почву для обобщений. Так вот, что им в действительности требуется, даже самые солидные клиенты не знают точно почти никогда. Чего хочется, знает один из десяти. И хорошо, если хоть один из полусотни будет знать, как это должно быть сделано. А самый верный способ загубить дело на корню — это начать вместе с ними метаться в их поисках себя. К профессионалу (если он не практикующий психолог) приходят все-таки не за этим, а за решением конкретной проблемы. Вот ее и нужно решить так, как подсказывает опыт, стандарты и правила отрасли, с максимальной тщательностью и в рамках бюджета. 🙂 Да, клиента можно и нужно попытать, выясняя задачи, которые должен решить перевод. Ему нужно предложить варианты решения, показать возможные пути и раскрыть перспективу. Но любые заигрывания в духе мифологемы из заголовка при этом неуместны абсолютно уже хотя бы потому, что переводят все дело из плоскости решения проблемы в плоскость психотерапии и внушения. И плоскости эти взаимоисключающие, потому что ресурсы исполнителя конечны, так что хорошо он в итоге (и в лучшем случае) все равно сделает что-то одно. А потребность в качественной услуге так и останется висеть в этом маркетинговом тумане увесистой гирей над головой заказчика. Любопытно, что дихотомию эту уловить оказывается довольно сложно коллегам, чье вхождение в профессию пришлось уже на XXI столетие. Казалось бы, уж их рассудок не должен быть зашорен никакими догмами? Объяснения у меня нет, пока в качестве рабочей гипотезы подозреваю, что сказывается агитационная проработка темы в СМИ и общественном сознании. Собственно, и это размышление родилось по мотивам одной такой беседы. Оптимистичного резюме к этим мыслям тоже нет, есть только надежда на здравый смысл и его волшебную способность со временем пробиваться сквозь любой морок. |
||||
|
Объять необъятное – попытка №1 |
||||
|
Весенние размышления об изношенности любимой клавиатуры как-то незаметно подвели к осознанию вполне очевидного факта: а ведь большинство типичной потребительской (как и условно “игровой”) периферии из компьютерных магазинов – либо откровенная копеечная дрянь, либо примерно такая же ерунда, только с фирменными фенечками и в стильной упаковке. Отпихивая так и лезущие в голову ассоциации с миром переводов, решил изучить вопрос поглубже. Все-таки большую часть времени взаимодействуем мы с компьютером именно через периферию, так что любая оптимизация этого “бутылочного горлышка” обещает либо прямую прибыль, либо экономию средств и здоровья. Наиболее доступной альтернативой вездесущим мембранным моделям оказались так называемые механические. С ними я планировал разобраться за пару вечеров, да только получилось все иначе. Начал изучение, как принято, с зарубежного опыта. И сразу же едва не оказался засыпанным ворохом открытий и откровений. Во-первых, обнаружилось, что клавиатуры делятся не только на дешевые и дорогие, но и на десятки, если не сотни, подвидов: — по типу переключателей и материалам; — по типу контроллера (программируемый или нет); — по трактовке эргономики производителем (традиционные, радикально эргономичные и все промежуточные стадии между этими двумя крайностями); — по поддерживаемой раскладке; — по дополнительному функционалу; -… и так далее чуть ли не до бесконечности. При этом каждое отличие вполне способно превратить давно знакомую “клаву” в совершенно новое по ощущениям, реакции и производительности устройство, сделать работу пыткой или удовольствием. Во-вторых, подтвердилось предположение о том, что изучать предмет по ассортименту компьютерных сетей предельно сложно, т.к. представленные там “геймерские” модели обычно выглядят и работают как пародии на модели профессиональные (которые в наше отечество, увы, почти никто не возит). В-третьих, выяснилось, что есть на свете сообщества людей, которые уже успели прогуляться по всем граблям выбора и поиска, опробовали основные разновидности и давным-давно опубликовали массу отзывов, впечатлений и чуть ли не исследований на эту тему. В первых рядах выступают такие ресурсы как Geekhack, Deskthority, Overclock.net. В общем, вскрылся интереснейший культурный пласт. Естественно, пересказать все в одном посте (посту?) нет никаких шансов, но хотя бы привести основные явки, пароли ссылки и адреса можно. К счастью, полезную привычку делиться опытом и у нас еще не все изжили полностью, так что на славном Хабре, например, легко обнаружить кладезь информации по теме, в котором отдельной жемчужиной выделяется сравнительно свежий переводной путеводитель (к слову, в хабровских обсуждениях комментарии зачастую содержат больше интересного, чем исходные статьи). Для людей, знакомых с миром техники, там не будет революционных новостей, но, как выясняется, и человеческая анатомия устроена достаточно консервативно, а более-менее цельная картина из этих кусочков уже начинает складываться. Насколько оправданы затраты времени и финансовые вложения в такую периферию, каждый решает сам, ну а я за время исследования обзавелся несколькими экземплярами и пока ни об одном из этих приобретений не пожалел. |
||||
|
Повседневное |
||||
|
А вот кому экспонатов для викторины «угадай самопальную локализацию с первого взгляда»?
|
||||
|
Немного практической математики |
||||
|
Как пишут в большинстве спецификаций на клавиатуры, ресурс мембранных моделей (95% ассортимента в любом магазине) составляет 5 000 000 нажатий. Что это означает применительно к переводческой работе? Предположим, что длина максимально условного среднего слова — 5 символов. 5 000 000 / 5 = 1 000 0000 слов Предположим, что средний переводчик за день одолевает около 2,5k слов плюс еще успевает набрать слов 500-1000-до-бесконечности помимо прямой производительной работы. 🙂 1 000 000 / 3 000 = 333,33 Понятно, что настоящие математики над такими исходными допущениями смеются еще в детском саду. Понятно, что нагрузка будет неравномерной, и максимальный износ придется на буквенно-цифровые блоки, пробел и символы пунктуации. Тем не менее, в любом раскладе получается, что даже работающий не в самом интенсивном режиме переводчик имеет вполне ощутимый шанс “убить” свой рабочий инструмент менее чем за год. И практический опыт подсказывает, что допущения эти на деле не так уж далеки от реальности. К чему посещают такие раздумья? Да просто однажды начинаешь замечать, что когда-то ласкавший слух шепот любимой MS Ergo 4000 сменился ее же натужным скрипом и дребезгом. И ничего тут не поделать, все закономерно. Остается только опять отправиться в магазин за ее сестрой-близнецом. Или все-таки в очередной раз поискать совершенства? |
||||
|
Сделайте мне развидеть это |
||||
|
Вышла свежая и долгожданная версия приложения из числа известных если и не всем, то очень многим.  Чего смотришь?! Давай, жми мышь, импортируй! Ну что тут скажешь, разработчикам виднее, что с их детищем следует делать. С замиранием сердца жду окончания установки. Чувствую, предстоят мне новые открытия в родном языке и, как по наивности казалось, давно знакомой области компьютерной техники. |
||||
|
Про неочевидное удобство |
||||
|
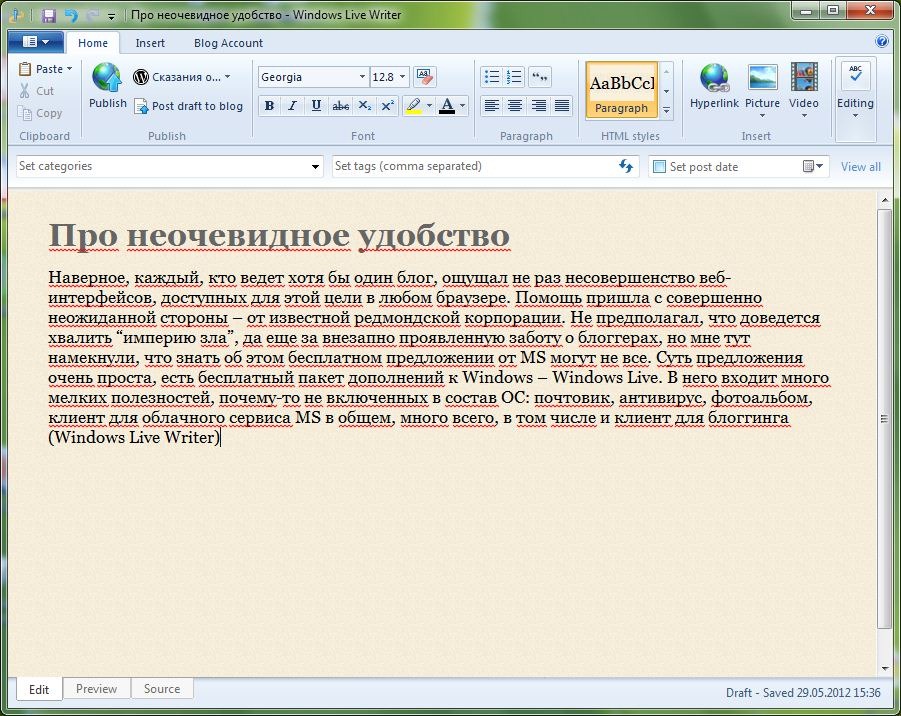
Наверное, каждый, кто ведет хотя бы один блог, ощущал не раз несовершенство веб-интерфейсов, доступных для этой цели в любом браузере. Помощь пришла с совершенно неожиданной стороны – от известной редмондской корпорации. Не предполагал, что доведется хвалить “империю зла”, да еще за внезапно проявленную заботу о блоггерах, но мне тут намекнули, что знать об этом бесплатном предложении от MS могут не все. Суть предложения очень проста, есть бесплатный пакет дополнений к Windows – Windows Live. В него входит много мелких полезностей, почему-то не включенных в состав ОС: почтовик, антивирус, фотоальбом, клиент для облачного сервиса MS, в общем, много всего, в том числе и клиент для блоггинга (Windows Live Writer). Выглядит его интерфейс вот так:
Клиент спокойно подключается к нашим блогам на trworkshop.net, работает без особых нареканий, поддерживает все очевидные функции и (если покопаться) некоторые из неочевидных. Взять его (и прочие компоненты Live) можно, например, здесь: http://windows.microsoft.com/en-US/windows/home Наверняка существуют и более удобные специализированные приложения для этой цели, но это — бесплатно (для официальных пользователей, при установке проверяется подлинность ОС), не перегружено избыточно сложными настройками и притом вполне функционально. |
||||
|
Вчера! |
||||
|
Где, ну где находится тот питомник, из которого вполне взрослыми людьми выбираются и идут дальше по жизни персонажи, не имеющие представления о том, что любое дело требует времени? На вопрос, как скоро им требуется перевод, такие отвечают: «Сейчас». Если хочется атомно пошутить, то: «Вчера». На сообщение о том, что это невозможно, следует железобетонной убедительности аргумент: «Я заплачу» (ударение поставить по вкусу), на отказ — обида в крайней степени, если не хуже. И вроде бы понятно, что в любой крупной популяции должен быть определенный процент идиотов, но, черт возьми, его неуклонный рост в нашей временами начинает утомлять. |
||||
|
О грамотном подходе |
||||
|
Время от времени профессиональные ресурсы радуют публикациями, которые можно приводить как пример правильного подхода к делу: http://habrahabr.ru/blogs/macosxdev/138263/ Жаль только, что из многих тысяч разработчиков должное внимание таким вопросам уделяют единицы. |
||||
|
Обновления |
||||
|
Который уж день несказанно умиляет значок недавно установленной (и конечно, локализованной) программки для синхронизации некоего мобильного устройства: «Доступны новые обновления для… (имя программы)». Все жду, когда станут доступны старые. Если не дождусь, ей-богу, сменю устройство. |
||||
|